I am a PhD student and Research Assistant @Northeastern University College of Engineering, advised by Prof. Yun Raymond Fu @SmileLab. My research focuses on large language models (LLMs) and multimodal large language models (MLLMs).

Kuo Yang
PhD | Research Assistant
About
Recent
🚀 Looking for Spring 2026 Internship Opportunities! 🚀
Last updated: Nov 15, 2025
Journey
2025

PhD Intern
Cambridge, MASanofi
May 2025 - Dec 2025
- Conducted research on tabular data understanding and question answering (QA) with LLMs using multi-agent chain-of-thought (CoT), focusing on improving reasoning and accuracy and reducing token usage over structured datasets.
- Integrated Weave and W&B functions into the CTD project for experiment tracking and data logging, enhancing reproducibility and collaboration in structuring regulatory submissions (clinical, preclinical, and quality data).
- Contributed to CI/CD workflows by developing automated tests and writing Lambda test code to validate code quality and ensure reliability of new commitments.
2024

PhD in Computer Engineering
Boston, MANortheastern University
Sep 2024 - Present
- Supervisor: Prof. Yun Fu (Raymond)
2024

AI Infrastructure Engineer
San Francisco, CAbitHuman Inc.
May 2024 - Sep 2024
- Optimized LLM performance by refining Retrieval-Augmented Generation (RAG) pipelines and prompt design to improve response quality and relevance.
- Designed and implemented real-time speech interruption mechanisms to enhance coherence in user-agent interactions.
- Deployed scalable, containerized digital agents on Kubernetes, streamlining deployment and ensuring reliability across environments.
2023

AI Engineer
Boston, MAAInnnovation Labs
Nov 2022 - Apr 2024
- Human Body Measurement Project: Developed a robust anthropometric body measurement pipeline using the SMPL framework to extract precise measurements from 3D human mesh data.
- Digital Human Project: Built a real-time digital agent by integrating TTS, STT, LLMs, and Speech-to-Image generation.
- Sleep Apnea Project: Created a cross-platform Flutter app utilizing Firebase as backend to support couples managing sleep apnea.
2022
M.S. in Electrical and Computer Engineering
Boston, MANortheastern University
Sep 2022 - Apr 2024
- Concentration: Machine Learning, Computer Vision, and Algorithms
2018

B.S. in Optoelectronic Information Science and Engineering
Shenzhen, ChinaShenzhen University
Sep 2018 - Jul 2022
- Activities: Class President, Officer of Academic Department
- Honor: First Prize of Innovation and Entrepreneurship, First Prize of Outstanding Student Leader
Publications
Abstract
Recent studies have uncovered an interesting phenomenon: unimodal foundation models tend to learn convergent representations, regardless of differences in architecture, training objectives, or data modalities. However, these representations are essentially internal abstractions of samples that characterize samples independently, leading to limited expressiveness. In this paper, we propose The Indra Representation Hypothesis, inspired by the philosophical metaphor of Indra's Net. We argue that representations from unimodal foundation models are converging to implicitly reflect a shared relational structure underlying reality, akin to the relational ontology of Indra's Net. We formalize this hypothesis using the V-enriched Yoneda embedding from category theory, defining the Indra representation as a relational profile of each sample with respect to others. This formulation is shown to be unique, complete, and structure-preserving under a given cost function. We instantiate the Indra representation using angular distance and evaluate it in cross-model and cross-modal scenarios involving vision, language, and audio. Extensive experiments demonstrate that Indra representations consistently enhance robustness and alignment across architectures and modalities, providing a theoretically grounded and practical framework for training-free alignment of unimodal foundation models.
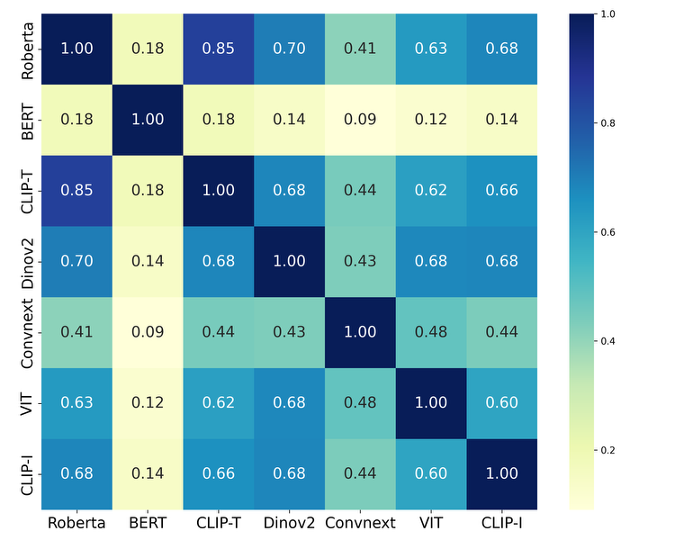
Representation Potentials of Foundation Models for Multimodal Alignment: A Survey
In Proceedings of EMNLP 2025
A comprehensive survey investigating the representation potentials of foundation models for multimodal alignment, synthesizing evidence from vision, language, speech, and neuroscience to understand cross-modal transfer capabilities.
Abstract
Foundation models learn highly transferable representations through large-scale pretraining on diverse data. An increasing body of research indicates that these representations exhibit a remarkable degree of similarity across architectures and modalities. In this survey, we investigate the representation potentials of foundation models, defined as the latent capacity of their learned representations to capture task-specific information within a single modality while also providing a transferable basis for alignment and unification across modalities. We begin by reviewing representative foundation models and the key metrics that make alignment measurable. We then synthesize empirical evidence of representation potentials from studies in vision, language, speech, multimodality, and neuroscience. The evidence suggests that foundation models often exhibit structural regularities and semantic consistencies in their representation spaces, positioning them as strong candidates for cross-modal transfer and alignment. We further analyze the key factors that foster representation potentials, discuss open questions, and highlight potential challenges.

Meta-Review Auto-Generation via Long-Context Modeling
In Preparation for Submission to ACL 2026
Proposed a long-context modeling approach for automated meta-review generation using LLMs, introducing MetaSum—the largest meta-review dataset—and a multi-role dialogue-style training framework.
Abstract
Meta-review auto-generation (MRAG) has emerged as a promising solution to accelerate academic publishing by automatically generating structured, concise meta-reviews with minimal human intervention. Although existing MRAG methods have shown feasibility, they are limited by data constraints, suboptimal modeling strategies, and inefficient training paradigms. In this paper, we propose a novel approach to MRAG that overcomes these limitations from three key perspectives. First, we introduce MetaSum, the largest and most up-to-date meta-review dataset, covering 31 conferences, 225 venues, and 52,993 submissions across various research domains. Second, unlike prior methods that truncate lengthy reviews, we treat MRAG as a long-context modeling task to retain complete textual information. Third, we develop a multi-role, dialogue-style training framework with efficient end-to-end optimization, fully leveraging LLMs for meta-review generation. Extensive experiments demonstrate that our approach significantly outperforms existing MRAG baselines and state-of-the-art LLMs. Our dataset and code will be made open-source.

Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Submitted to ICLR 2026
Introduced Ref-Adv, a challenging REC benchmark with 5k expressions featuring hard distractors and complex reasoning facets.
[Paper] Coming Soon
[Code] Coming Soon
[Dataset] Coming Soon
Abstract
Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual rea- soning and grounding: (i) many expressions are very short, leaving little reason- ing demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expres- sions with only the information necessary to uniquely identify the target. The dataset contains 5k expressions on real images (1k human authored, 4k human verified), curated with hard distractors and annotated with reasoning facets includ- ing negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and Ref- COCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
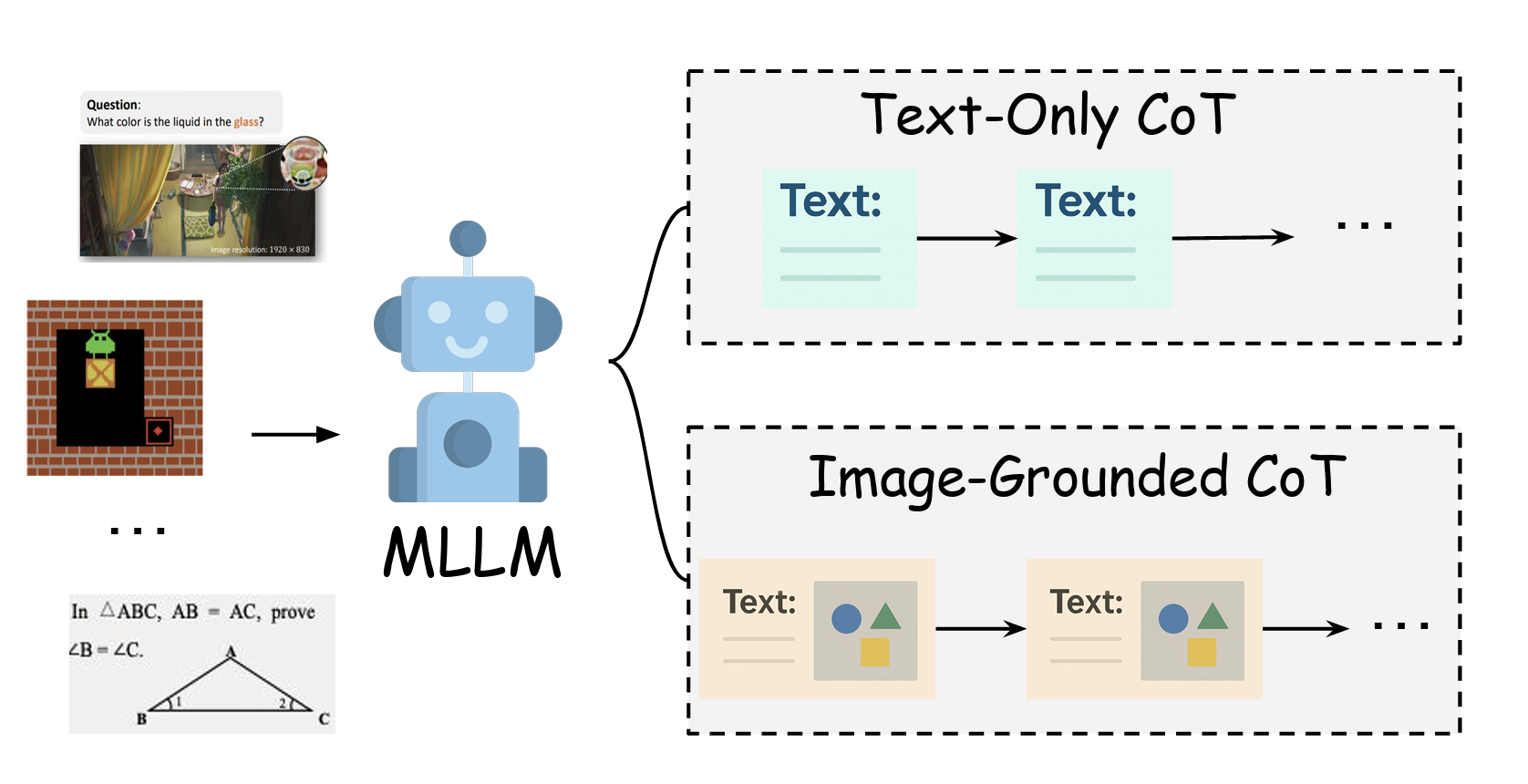
Revealing the Seen, Imagining the Beyond: A Survey of Image-Grounded Chain-of-Thought Reasoning in Multimodal LLMs
Submitted to EACL 2026
A comprehensive survey on Image-Grounded Chain-of-Thought (IG-CoT) reasoning in multimodal LLMs, covering prompting, supervised fine-tuning, and reinforcement learning techniques for detail-oriented and imagined-world reasoning.
[Paper]
[Code] Coming Soon
Abstract
Multimodal large language models (MLLMs) are making rapid strides in complex visual reasoning. This survey synthesizes the emerging paradigm of Image-Grounded Chain-of-Thought (IG-CoT), where models ground intermediate inferences by interleaving textual rationales with visual state updates. We formalize IG-CoT, present a method-centric taxonomy covering prompting, supervised fine-tuning, and reinforcement learning, and map these techniques to representative benchmarks. Our analysis identifies two domains where IG-CoT offers significant advantages: detail-oriented reasoning requiring meticulous perception, and imagined-world reasoning for simulating unseen states in games, geometry, and planning. We discuss the practical trade-offs of current methods regarding controllability, data, and compute. We conclude by highlighting key challenges—efficiency, data quality, and generative capabilities—and outlining promising future directions, including lightweight architectures, richer intermediate supervision, and method-aware evaluations that better assess faithfulness and long-horizon reasoning.
Projects

Human Body Measurements
Developed a robust anthropometric body measurement pipeline using the SMPL framework to extract precise measurements from 3D human mesh data. Built a Python module to calculate key body dimensions from control points, scaled according to height and refined using correction factors for improved accuracy and repeatability.
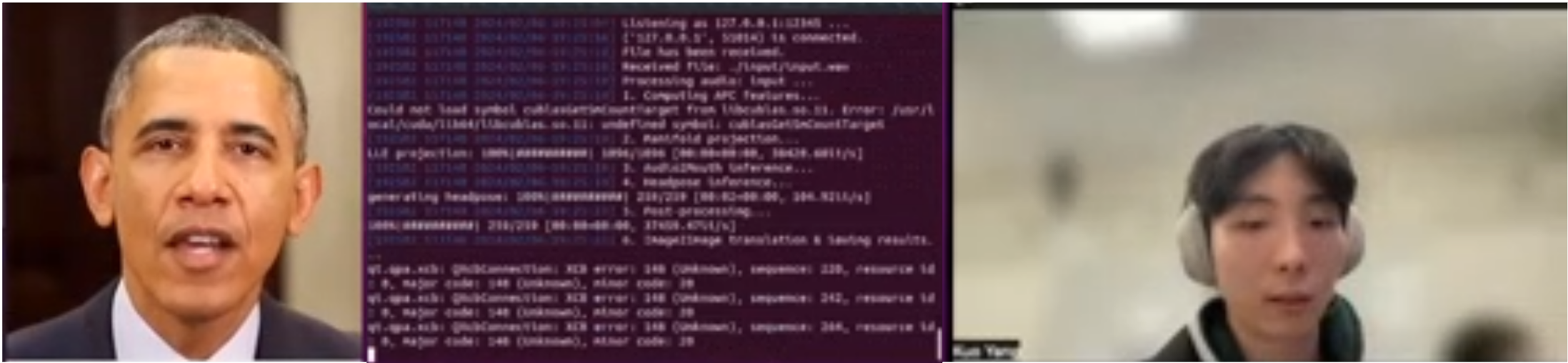
Real-time Digital Human
Built a real-time digital agent by integrating TTS, STT, LLMs, and Speech-to-Image generation, synchronizing all components to deliver a seamless, interactive user experience.